Spindle 0.1 is out!
Table of Contents
- Thanks 💖
- Scientific Computing in Rust
- Goals
- The basic_range macro
- Error handling
- Why cudarc over rust-cuda?
- Other features?
I am quite proud of the ergonomics. CUDA is always hard to deal, so I am using procedural macros to regulate what functions it weaves, starting from Embarrassingly Parallel problems and inducting up to Data Parallel.
Thanks 💖
I am especially grateful to friends and interested Rustaceans for their support! Feedback ranged from nodding in agreement, design suggestions, memes, and most importantly, helping me come up with the name! We can't not take inspiration from rayon, the lighter than silk CPU parallelization crate. Honorable mentions to serger, throstle, coreduroy (sigh), and curayon.
Scientific Computing in Rust
The conference was fantastic! The organizers did a fantastic job organizing the talks, communicated clearly, and facilitated a Gather Town social hour that was very hard to leave. It was heartwarming to see 100+ people show up for the first event. Special shoutouts to Gonzalo, Miguel, Ryan, and Sarah. Great job on your talks, everyone. It was a pleasure to meet you, and I look forward to collaborating 🔬.
Also, what a beautiful coincidence to be releasing the first draft of spindle after nearly 10 hours of directly or tangentially related talk! I am inspired to meet the need for ergonomic GPGPU parallelism in Rust.
Goals
What do we want
to do? Some intrusive thoughts emerge.
How should we handle generics? Trait bound? Arrays? Lifetimes? Shared static memory? Monomorphization? Crate dependencies? Recursive dependencies? Ooh! I have an idea for a HPC-empowered iterator! And a structure that handles filter maps! I bet we can map arrays, iterators, and vectors! Yeah, the ergonomics are a huge deal. How about a config struct parsed with
nomorserdeso the user has access to... Ooooooh wait! I have an idea to optimize allocations. It only involves some pointer recasting, then we'll just widen the memory buffer... oh but now that means anothernullptrcheck, but that's fine, we can just pack that into the error variant. I know a good name for the data structure... we need another trait with a method like... and we should call it...
breathes Hey. Take it easy on yourself. Everything you just said is extremely hard. This is your first macro crate, and yes, macros are hard to write. GPGPU is hard. FFI is hard. Unsafe code is hard and unsafe. You got this, but please be kind to yourself.
What about just a range map that uses the GPU to map n: i32 to [foo(0), ..., foo(n-1)]?
One final intrusive thought
*that shouldn't be so hard 😉
Spoiler to nobody: it was.
The basic_range macro
The attribute macro basic_range hides the hard work of safely(?) and correctly(?) interfacing with GPGPU APIs by:
- regulating the signature of
square_over_two - generating a ptx crate
square_over_two - compiling the crate and emitting
$KERNEL/path/to/kernel.ptx - defining
trait _SquareOverTwowith aGeneral Associated Type - implementing
_SquareOverTwofori32withReturn = Vec<i32> - defining the standalone launcher
_square_over_two
Almost every step here involves something tricky. Writing a macro severs the tie to many ergonomic qualities of Rust with a layer of indirection. Running arbitrary code at compile time and rewriting a TokenStream (uh, I think you mean proc_macro2::TokenStream) is hard! There are ways to claw some of them back, but it's another thing to learn. Don't reach for macros until you need them.
Let's dive in.
Regulate square_over_two
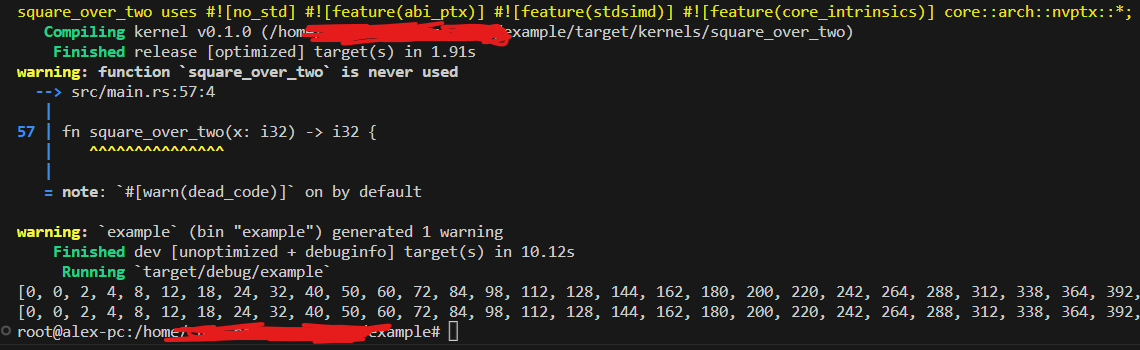
We start with a simple mapping function that uses the GPU to map 0..n with
Let's further restrict ourselves to a single i32 parameter with a primitive number return type (u32, f64, etc). Launching CUDA kernels is inherently unsafe and the registers must be manually managed ourselves. Better to start simply and correctly here.
Generics? Unsupported. Monomorphization? Maybe for 1.1.0. Lifetimes? what does that even mean here???
Generate the square_over_two ptx crate
The $NAME = square_over_two crate lives at $KERNEL = $PROJECT/kernels/square_over_two/ with boilerplate files $KERNEL/{Cargo.toml, rust-toolchain.toml, .cargo/config.toml, src/lib.rs}. The toml files configure the crate for ptx emission. In addition, square_over_two is copied to $KERNEL/src/device.rs, renamed as device.
// lib.rs
use *;
!
pub unsafe extern "ptx-kernel"
Do you see why we started with i32?
If you want to play with the ptx crate, rust-analyzer will be fully on-board thanks to the toml files! Note that any changes you make will be overridden by the macro at will, so copy it elsewhere for your experiments.
This code is deliberately not optimized for locality or performance. It performs unnecessary bounds checks. I am resisting the urge for untested and unbenchmarked changes. If you have suggestions, please submit them as issues and pull requests.
Emit $KERNEL/path/to/kernel.ptx
We use the experimental #![feature(abi_ptx)] and std::process::Command to run
Colored terminal output is logged and paired with a colored about the use of nightly Rust content:
use *;
It's not perfect, but the warning should be visible to anyone compiling the code.
Define the trait _SquareOverTwo
The GAT Return is the desired return type, e.g., Box<[i32]> or Vec<i32> The only method is
unsafe ;
Implement _SquareOverTwo for i32
Here, Return = Vec<i32>.
Before interfacing with our ptx code, we unsafely allocate uninitialized memory, manually check for a nullptr, and unsafely initialize a host Vec.
We then use cudarc to initialize a CudaDevice, consume kernel.ptx, unsafely asyncrhonously launch a CudaFunction, and unsafely reclaim data from the device.
Hooray! We can
let foo = unsafe .unwrap;
println!;
Define the standalone launcher _square_over_two
This free functions has signature
unsafe It performs a comparable sequence of allocations.
We can now
let bar: = unsafe .unwrap;
println!;
Error handling
The function signatures should tell the story and the unwrap()'s log our progress. I believe the memory management is correct, but I would love inspection from fresh eyes. Feedback, such as a github issue or PR, is welcome.
Why cudarc over rust-cuda?
No specific reason, outside of familiarity. It would be fantastic to switch between them via feature flags. PRs welcome, but the Minimum Viable Product comes first.
Other features?
Too many to list. No matter what we do, every feature should be ergonomic, correct, and safe, all tied as Priority #1. Next comes performance, as much as I love it.